前言:MySQL的Innodb存储引擎的索引分为两大类:聚集索引和非聚集索引
一、聚集索引是什么?
MySQL的Innodb存储引擎的索引分为两大类
- 聚集索引
- 非聚集索引
理解聚集索引和非聚集索引可通过对比汉语字典的索引:
- 聚集索引–>拼音排序:存储的记录(数据库中是行数据、字典中是汉字的详情记录)是按照该索引排序的
- 非聚集索引–>笔画排序:笔画索引,虽然笔画相同的字在笔画索引中相邻,但是实际存储页码却不相邻
正文内容按照一个特定维度排序存储,这个特定的维度就是聚集索引;
Innodb存储引擎中行记录就是按照聚集索引维度顺序存储的,Innodb的表也称为索引表;因为行记录只能按照一个维度进行排序,所以一张表只能有一个聚集索引。
非聚集索引索引项顺序存储,但索引项对应的内容却是随机存储的;
二、举个例子
create table student (
`id` INT UNSIGNED AUTO_INCREMENT,
`name` VARCHAR(255),
PRIMARY KEY(`id`),
KEY(`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
该表中主键id是该表的聚集索引、name为非聚集索引;
表中的每行数据都是按照聚集索引id排序存储的;
比如要查找name=’Arla’和name=’Arle’的两个同学,他们在name索引表中位置可能是相邻的,但是实际存储位置可能差的很远。name索引表节点按照name排序,检索的是每一行数据的主键。聚集索引表按照主键id排序,检索的是每一行数据的真实内容。
也就是说查询name=’Arle’的记录时,首先通过name索引表查找到Arle的主键id(可能有多个主键id,因为有重名的同学),再根据主键id的聚集索引找到相应的行记录;
每张表只有一个聚集索引,因为聚集索引在精确查找和范围查找方面良好的性能表现(相比于普通索引和全表扫描),聚集索引就显得弥足珍贵,聚集索引选择还是要慎重的。
从宏观上分析下聚集索引和普通索引的性能差异,还是针对上述student表:
select * from student where id >5000 and id <20000;
select * from student where name > 'Alie' and name < 'John';
第一条SQL语句根据id进行范围查询,因为(5000, 20000)范围内的记录在磁盘上按顺序存储,顺序读取磁盘很快就能读到这批数据。
第二条SQL语句查询(’Alie’, ‘John’)范围内的记录,主键id分布可能是离散的1,100,20001,5000…..;增加了随机读取数据页几率;所以普通索引的范围查询效率被聚集索引甩开几条街都不止;非聚集索引的精确查询效率还是可以的,比聚集索引查询只增加了一次IO开销
三、如何创建聚集索引?
下面是MySQL文档中关于索引的说明:文档说明
每个InnoDB表有一个特殊的指数称为聚集索引所在的行的数据存储。通常,聚集索引是主键的同义词。从查询,插入性能最好,和其他的数据库操作,必须了解InnoDB使用聚集索引来优化每个表最常见的查询和DML操作。
当你定义你的表的主键,InnoDB使用它作为聚集索引。为您创建的每个表定义一个主键。如果没有逻辑唯一的和非空的列或列集,添加一个新的自动增量列,它的值自动填充。
如果你不确定你的表的主键、唯一索引,MySQL定位第一所有键列不为空,InnoDB使用它作为聚集索引。
如果表没有主键或唯一索引InnoDB内部适用,生成一个隐藏的聚集索引为合成列包含行ID值gen_clust_index。行的ID,InnoDB分配在这样一个表中的行排序。行ID是一个6字节字段的单调增加,在插入新行。因此,行id命令的行在物理上是插入顺序。
总结如下:
- 如果一个主键被定义了,那么这个主键就是作为聚集索引
- 如果没有主键被定义,那么该表的第一个唯一非空索引被作为聚集索引
- 如果没有主键也没有合适的唯一索引,那么innodb内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个6个字节的列,改列的值会随着数据的插入自增。
InnoDB引擎会为每张表都加一个聚集索引,而聚集索引指向的的数据又是以物理磁盘顺序来存储的,自增的主键会把数据自动向后插入,避免了插入过程中的聚集索引排序问题。如果对聚集索引进行排序,这会带来磁盘IO性能损耗是非常大的,因此mysql表的主键一般为自增id
四、原理深入理解
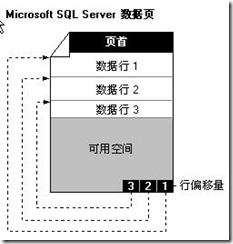
数据库文件存储是已页为存储单元的,一个页是8K(8192Byte),一个页就可以存放N行数据。我们常用的页类型就是数据页和索引页。一个页中除了存放基本数据之外还需要存放一些其他的数据,如页的信息、偏移量等,如下图所示。
虽然SQLServer是以页为单位存储数据,但是其分配空间是以一个盘区为单位的(8个页=64K),这样做的目的主要是为提高I/O的性能
一条索引记录中包含的基本信息包括:键值 + 逻辑指针。
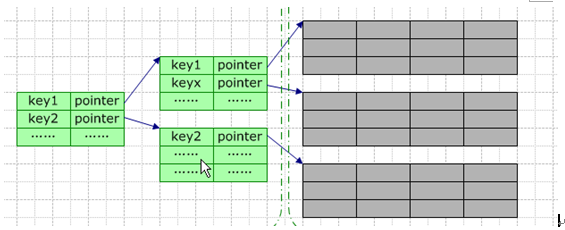
SQLServer中使用页为存储单元的,那么在建立索引时,其索引节点就是页了,然后树的键值就是存放到这些页(节点)中的。就是说表中的数据行就是存放到页上的,一个表有多个页构成,这些页以树的结构存放。
(1)聚集索引的结构
对于某个聚集索引,索引指向该聚集索引某个特定分区(数据页)的顶部。聚集索引的索引顺序就是数据排列顺序
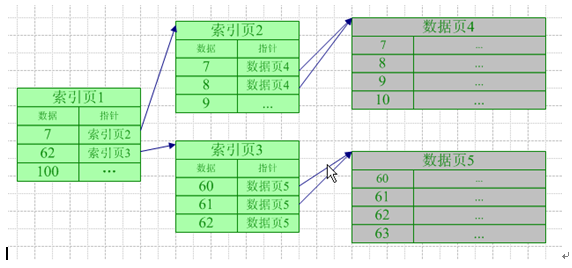
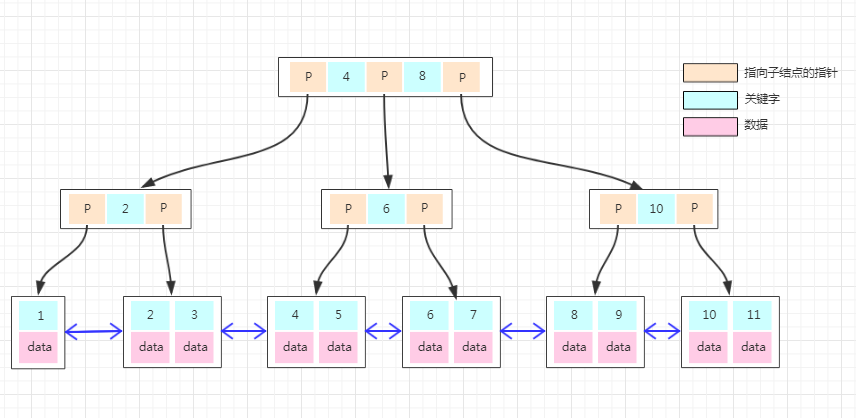
聚集索引与查询操作
- 如上图,在建立聚集索引后,当需要在根据此字段查找特定的记录时,数据库系统会根据特定的系统表查找的此索引的根,然后根据指针查找下一个,直到找到。数据查询时首先是对索引表查询,如果此时索引表在缓存中可以找到,则可以避免一次IO操作。在索引表中找到所需数据索引值后,就可以确定目标数据行所在的数据位置,从而读取数据。
聚集索引与插入和删除操作
- 插入数据时,首先根据索引找到对应的数据页,然后通过挪动已有的记录为新数据腾出空间,最后插入数据。
- 删除数据时将导致其下方的数据行向上移动以填充删除记录造成的空白。
- 对于数据的删除操作,可能导致索引页中仅有一条记录,这时,该记录可能会被移至邻近的索引页中,原索引页将被回收,即所谓的“索引合并”。同样插入数据页会更改索引。每一次索引更改都是一次IO操作。
- 聚集索引的建立会降低数据插入和删除的效率
(2)非聚集索引的结构
由于非聚集索引数据存储时无序的,所以在非聚集索引中指针包含数据行在数据页中的偏移量。即指针由 数据页 + 数据行偏移量 组成
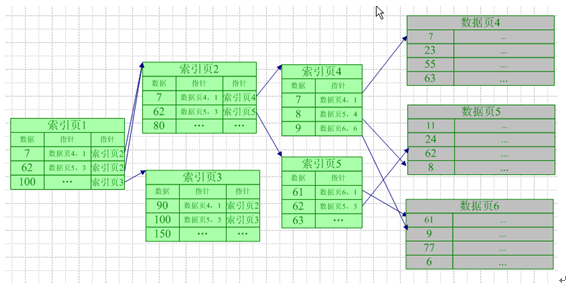
非聚集索引的存储结构与前面是一样的,不同的是在叶子结点的数据部分存的是聚集索引的key。所以通过非聚集索引查找的过程是先找到该索引key对应的聚集索引的key,然后再拿聚集索引的key到主键索引树上查找对应的数据,这个过程称为回表!回表势必会增加一次IO
非聚集索引的查询
- 如上图,在建立非聚集索引后,当需要在根据此字段查找特定的记录时,数据库系统会根据特定的系统表查找的此索引的根,然后根据指针查找,直到找到。数据查询时首先是对索引表查询,如果此时索引表在缓存中可以找到,则可以避免一次IO操作。在索引表中找到所需数据索引值后,就可以确定目标数据行所在的数据位置,从而读取数据。
非聚集索引的插入删除
- 如果一张表包含一个非聚集索引但没有聚集索引,则新的数据将被插入到最末一个数据页中,然后非聚集索引将被更新。如果也包含聚集索引,该聚集索引将被用于查找新行将要处于什么位置,随后,聚集索引、以及非聚集索引将被更新。
如果在删除命令的Where子句中包含的列上,建有非聚集索引,那么该非聚集索引将被用于查找数据行的位置,数据删除之后,位于索引叶子上的对应记录也将被删除。如果该表上有其它非聚集索引,则它们叶子结点上的相应数据也要删除
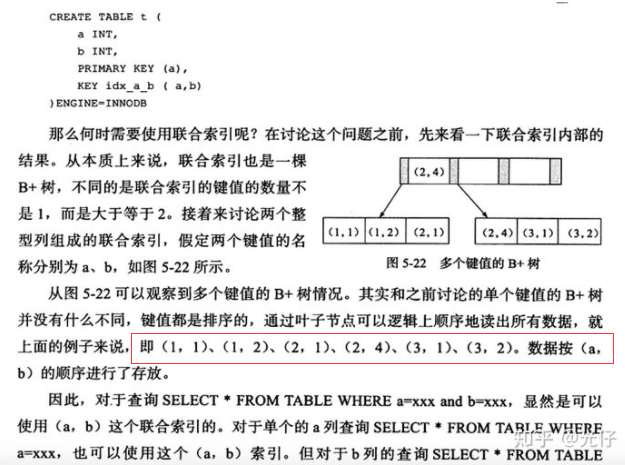
五 解决回表问题:复合索引
建立两列以上的索引,即可查询复合索引里的列的数据而不需要进行回表二次查询,如index(col1, col2),执行下面的语句
select col1, col2 from t1 where col1 = '213';
要注意使用复合索引需要满足最左侧索引的原则,也就是查询的时候如果where条件里面没有最左边的一到多列,索引就不会起作用。
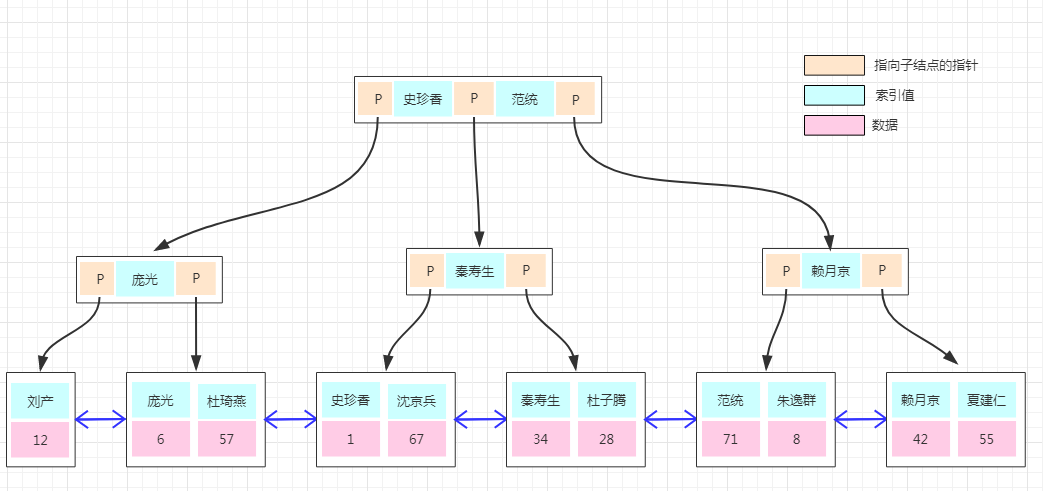
复合索引结构:
键的排列规则为:按照位进行排列,优先保证高位有序,其次保证低位有序
之所以会有最左前缀匹配原则和联合索引的索引构建方式及存储结构是有关系的。
首先我们创建的index_bcd(b,c,d)索引,相当于创建了(b)、(b、c)(b、c、d)三个索引,看完下面你就知道为什么相当于创建了三个索引。
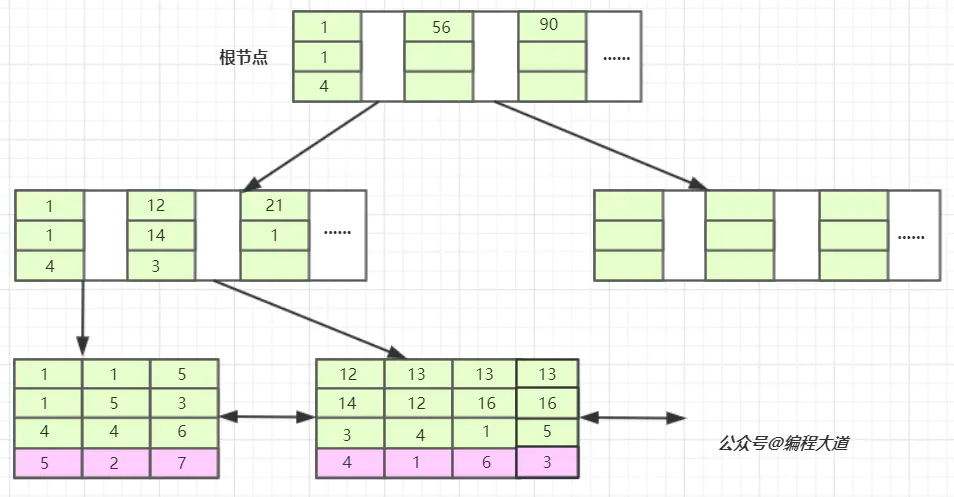
我们看,联合索引是首先使用多列索引的第一列构建的索引树,用上面idx_t1_bcd(b,c,d)的例子就是优先使用b列构建,当b列值相等时再以c列排序,若c列的值也相等则以d列排序。我们可以取出索引树的叶子节点看一下。
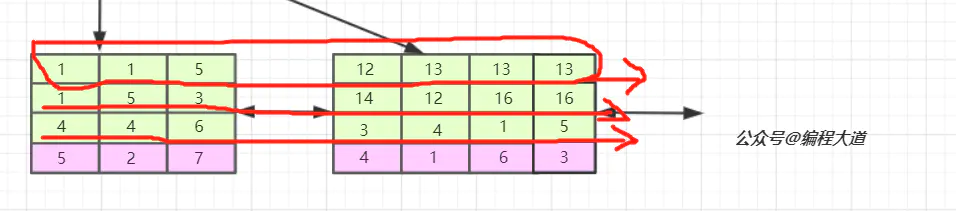
索引的第一列也就是b列可以说是从左到右单调递增的,但我们看c列和d列并没有这个特性,它们只能在b列值相等的情况下这个小范围内递增,如第一叶子节点的第1、2个元素和第二个叶子节点的后三个元素。 由于联合索引是上述那样的索引构建方式及存储结构,所以联合索引只能从多列索引的第一列开始查找。所以如果你的查找条件不包含b列如(c,d)、(c)、(d)是无法应用缓存的,以及跨列也是无法完全用到索引如(b,d),只会用到b列索引。
一些实例
select * from T1 where b = 12 and c = 14 and d = 3;-- 全值索引匹配 三列都用到
select * from T1 where b = 12 and c = 14 and e = 'xml';-- 应用到两列索引
select * from T1 where b = 12 and e = 'xml';-- 应用到一列索引
select * from T1 where b = 12 and c >= 14 and e = 'xml';-- 应用到bc两列列索引及索引条件下推优化
select * from T1 where b = 12 and d = 3;-- 应用到一列索引 因为不能跨列使用索引 没有c列 连不上
select * from T1 where c = 14 and d = 3;-- 无法应用索引,违背最左匹配原则
参考资料
- MySQL聚集索引和非聚集索引
- 聚簇索引和聚簇索引介绍
- MySQL聚集索引和非聚集索引
- MySQL聚集索引和非聚集索引(推荐阅读)
- mysql复合索引的底层数据结构?
- 联合索引在B+树上的存储结构及数据查找方式
