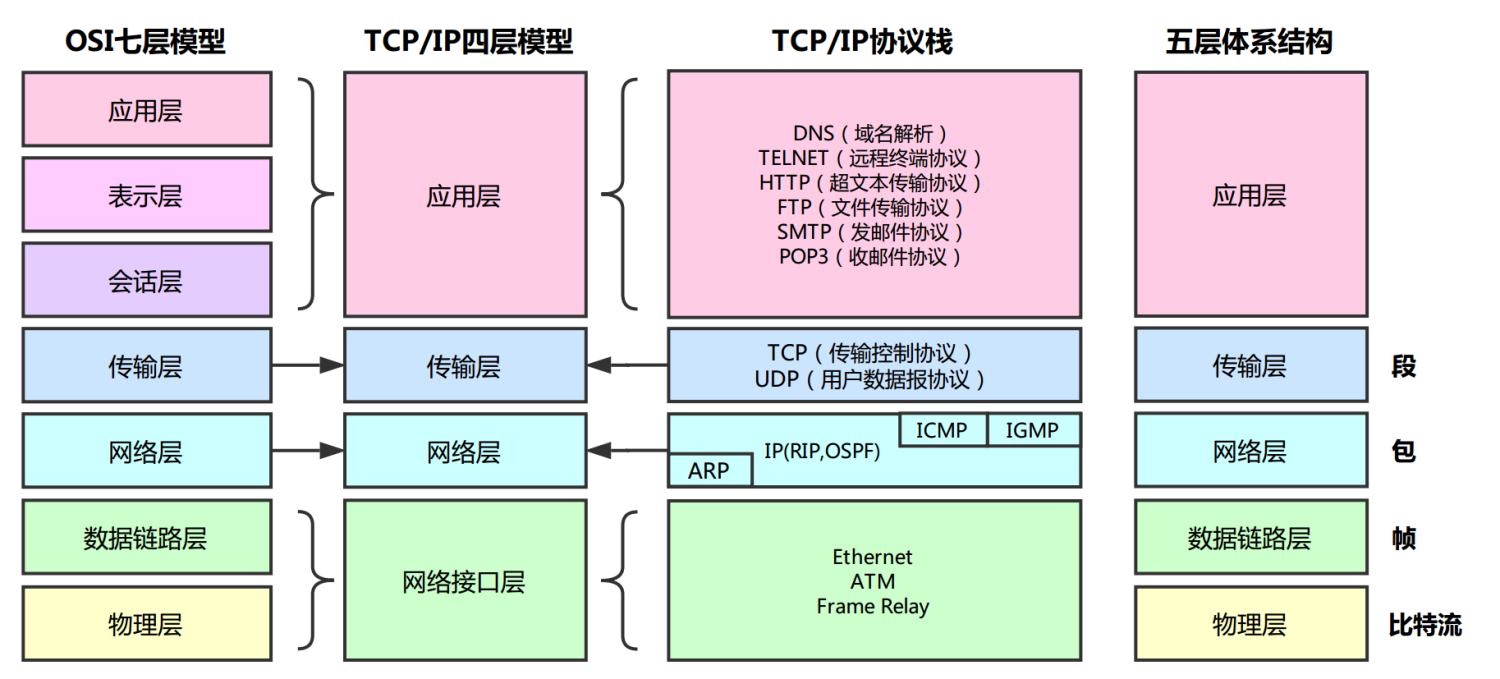
1、OSI七层模型
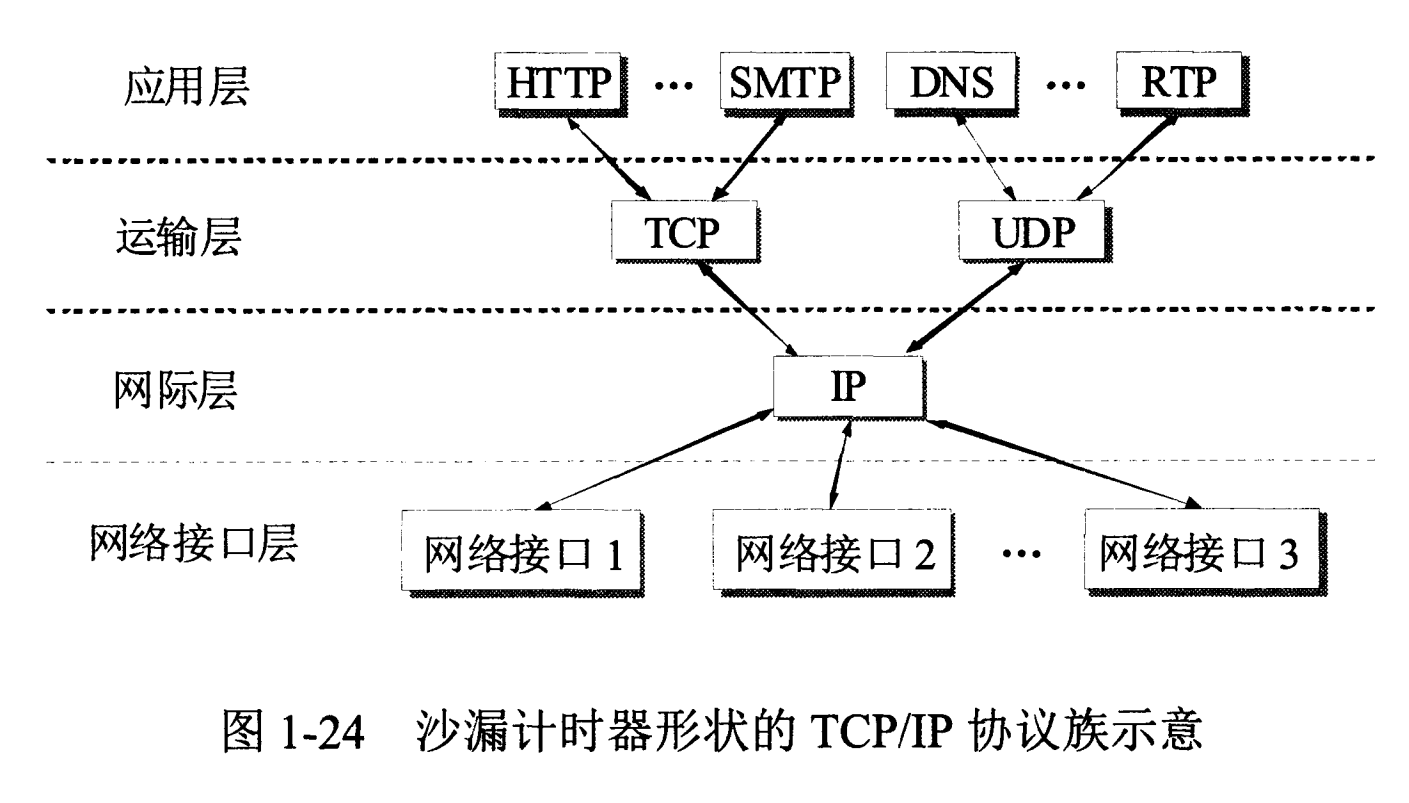
2、TCP和UDP的区别
1.TCP面向连接,UDP无连接。
2.TCP面向字节流(文件传输),UDP是面向报文的,UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对IP电话,实时视频会议等)。
3.TCP首部开销20字节,UDP的首部开销小,只有8个字节。
4.TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付。
5.每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信。
6.TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道。
3、TCP如何保证数据的可靠传输的?
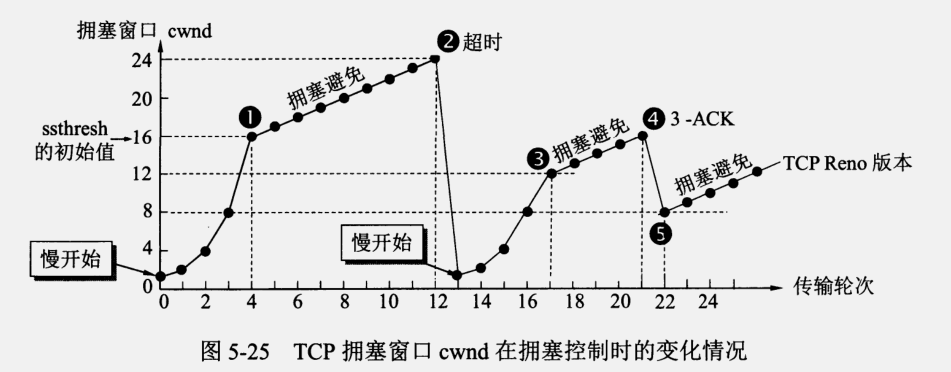
应用数据被分割成TCP认为最适合发送的数据块。
- 超时重传:当TCP发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。TCP给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
- 流量控制:TCP连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP使用的流量控制协议是可变大小的滑动窗口协议。
- 拥塞控制:当网络拥塞时,减少数据的发送。
- 校验和:TCP将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP将丢弃这个报文段和不确认收到此报文段。TCP的接收端会丢弃重复的数据。
4、TCP三次握手的过程
第一次握手:建立连接时,客户端发送 SYN 包(syn=j)到服务器,并进入 SYN_SEND 状态,等待服务器确认;
第二次握手:服务器收到 SYN 包,必须确认客户的 SYN(ack=j+1),同时自己也发送一个 SYN 包(syn=k),即 SYN+ACK 包,此时服务器进入 SYN_RECV 状态;
第三次握手:客户端收到服务器的 SYN+ACK 包,向服务器发送确认包 ACK(ack=k+1),此包发送完毕,客户端和服务器进入 ESTABLISHED 状态,完成三次握手。
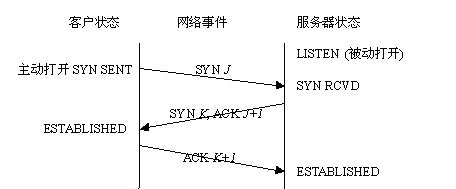
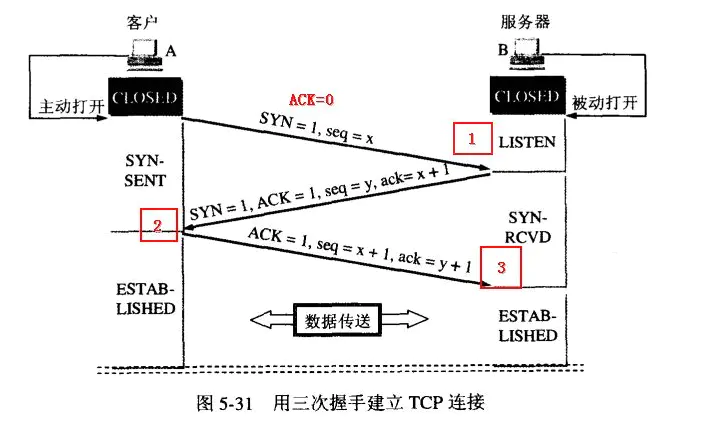
SYN:同步序号,用于建立连接过程
ACK:确认序号标志,为1时表示确认号有效,为0表示报文中不含确认信息,忽略确认号字段
5、为什么是三次握手,不是两次或者四次?
两次握手情况
两次握手有这样一个问题:客户端发出的无效请求在网络中滞留(新的请求代替了旧的)
比如说:
如果网络状况不好,客户端发送了两次请求,第二次请求建立连接成功,并在数据传送完之后释放连接,此时第一次请求恰好传送到了客户端
如果是两次握手就会发生下面的情况:
服务端因为接受到了请求,进行回复,两次握手完成,连接建立。但此时客户端并没有请求连接,并不会理睬服务端的确认。
这样就会造成一种结果:客户端并不会向服务端请求数据,服务端等待客户端请求数据,,会造成服务端资源的浪费
如果采用了三次握手呢?
- 服务端在响应了滞留在网络中的无效的请求后,向客户端发送了确认信息, //(B—->A)
- 但是此时客户端已经没有了建立连接的需求,所以并不会响应服务端, // (A不理会B)
- 服务端因没有接受到客户端的进一步的确认所以连接不会建立 //(建立连接失败)
四次握手情况
- A 发送同步信号SYN + A’s Initial sequence number
- B 确认收到A的同步信号,并记录 A’s ISN 到本地,命名 B’s ACK sequence number
- B发送同步信号SYN + B’s Initial sequence number
- A确认收到B的同步信号,并记录 B’s ISN 到本地,命名 A’s ACK sequence number·
很显然2和3 这两个步骤可以合并,只需要三次握手,可以提高连接的速度与效率。
5-1、SYN底层攻击原理
客户端只发送SYN包,而对服务器的ACKSYN包不回复,通过模拟大量IP,同时发送这样的请求,导致服务器端SYN-RCVD状态(放置于半连接队列)的连接过多,半连接队列大于系统设定的最大值,系统不再接受其他连接。
简单来讲,就是黑客制造大量客户端同时不进行第二次握手的异常连接,把服务器半连接队列撑爆了,没法接受其他正常连接
6、TCP四次挥手
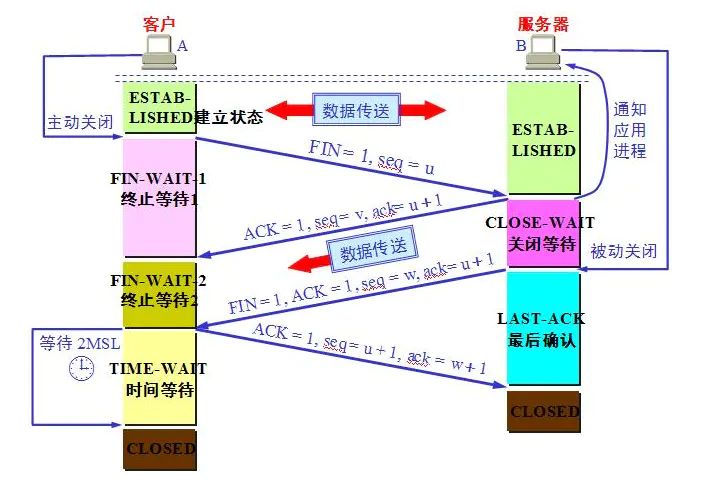
TCP连接是全双工的,因此每个方向都必须单独进行关闭。
1.客户端A发送一个FIN,用来关闭客户A到服务器B的数据传送,并发送一个自己的ISN(u)
2.服务器B收到这个FIN,它发回一个ACK,确认序号为收到的序号加1(u+1)。同时发送一个自己的ISN(v)
3.服务器B关闭与客户端A的连接,发送一个FIN、ACK给客户端A,确认号为收到的序号加1(u+1),与上一次不变。同时发送一个自己的ISN(w)
4.客户端A发送ACK报文确认,并将确认序号设置为收到序号加1(w+1),序列号就是上一次的确认号(u+1)
7、为什么是四次挥手
等待服务端未发送的数据传送完毕
** **
详细解释:
如果客户端想要停止向服务端发送数据,首先要停止发送数据,并且通知对方,第二步是等待服务器的回复。当然,服务器要向客户端停止发送数据,也得类似。
四次挥手是因为 TCP 是全双工的,两端能同时向对方发送数据,如果不足四次的话无法确定双方都没有数据发送了。
7-1、服务器TIME_WAIT状态过多
大量TIME_WAIT造成的影响:
在高并发短连接的TCP服务器上,当服务器处理完请求后立刻主动正常关闭连接。这个场景下会出现大量socket处于TIME_WAIT状态。如果客户端的并发量持续很高,此时部分客户端就会显示连接不上。
我来解释下这个场景。主动正常关闭TCP连接,都会出现TIMEWAIT。
为什么我们要关注这个高并发短连接呢?有两个方面需要注意:
\1. 高并发可以让服务器在短时间范围内同时占用大量端口,而端口有个0~65535的范围,并不是很多,刨除系统和其他服务要用的,剩下的就更少了。
\2. 在这个场景中,短连接表示“业务处理+传输数据的时间 远远小于 TIMEWAIT超时的时间”的连接。
这里有个相对长短的概念,比如取一个web页面,1秒钟的http短连接处理完业务,在关闭连接之后,这个业务用过的端口会停留在TIMEWAIT状态几分钟,而这几分钟,其他HTTP请求来临的时候是无法占用此端口的(占着茅坑不拉翔)。
单用这个业务计算服务器的利用率会发现,服务器干正经事的时间和端口(资源)被挂着无法被使用的时间的比例是 1:几百,服务器资源严重浪费。(说个题外话,从这个意义出发来考虑服务器性能调优的话,长连接业务的服务就不需要考虑TIMEWAIT状态。同时,假如你对服务器业务场景非常熟悉,你会发现,在实际业务场景中,一般长连接对应的业务的并发量并不会很高。
综合这两个方面,持续的到达一定量的高并发短连接,会使服务器因端口资源不足而拒绝为一部分客户服务。同时,这些端口都是服务器临时分配,无法用SO_REUSEADDR选项解决这个问题。
相关参数优化调整(当然得根据服务器的实际情况配置,这里着重讲参数意义):
既然知道了TIME_WAIT的用意了,尽量按照TCP的协议规定来调整,对于tw的reuse、recycle其实是违反TCP协议规定的,服务器资源允许、负载不大的条件下,尽量不要打开,当出现TCP: time wait bucket table overflow,尽量调大下面参数:
- 调大time_wait队列数
- 减小TIME_WAIT_2到TIME_WAIT的超时时间
- 修改系統默认的TIMEOUT时间
vim /etc/sysctl.conf
#time wait 最高的队列数
tcp_max_tw_buckets = 256000
调整次参数的同时,要调整TIME_WAIT_2到TIME_WAIT的超时时间,默认是60s,优化到30s:
net.ipv4.tcp_fin_timeout = 30
其它TCP本身的配合参数类似与synack重传次数、syn重传次数等以后介绍,优化后也是有所益处的。
#修改系統默认的TIMEOUT时间
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tw_reuse = 1
7-2、服务器CLOSE_WAIT状态过多
常见原因:数据库连接没有close()
今天在运行服务器的时候发现一个问题,问题的表现是客户端一直在请求,但是返回给客户端的信息是异常,服务端压根没有收到请求,查看了一下配置信息没有错误,首先查看了一下是不是服务器的连接已经满了,打开netstat命令发现服务器的连接有 大量的CLOSE_WAIT状态的socket,没怎么遇到这个问题,开始还真有段懵了,第一反应就是是不是客户端的问题(是不是出问题的第一反应都是别人的问题),但是马上补充了一下socket状态机的知识,发现这个状态是由于客户端关闭了socket连接,发送了FIN报文,服务端也发送了ACK报文,此时客户端处于FIN_WAIT_2状态,服务端处于CLOSE_WAIT状态,如下图:
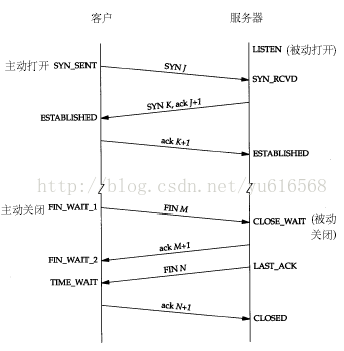
可以看出,出现问题的原因是由于我这边没有发送第二个FIN报文导致的,分明是我的问题啊,为什么服务器没有发送FIN报文呢?我的服务器使用的是嵌入式的jetty,连接管理应该都是它帮我管理的,重启了一下服务器发现服务器的CLOSE_WAIT开始的时候没有出现,之后逐渐的上升,貌似随着请求的数量逐渐增长的,而我这边的日志也非常奇怪,我会在收到请求的时候打印日志,然后在执行完毕的时候输出一个accesslog信息,发现日志中有入口的请求日志,但是accessLog没有增长,于是单步调试了一下,发现了问题:一个servlet的执行走到主流程就走不下去了,阻塞在数据库访问那一步上,具体表现就是获取不到数据库连接!
查看了一下代码,发现原来是自己创建连接,执行sql,完成之后没有关闭连接,OMG,这么愚蠢的错误,于是在所有的数据库操作的最后加上如下的代码:
finally {
DbUtils.closeQuietly(conn);
}
1、代码一定要规范,尤其是在写一些关于自愿申请的部分,一定要在写函数之前写上注释告诉自己别忘了释放资源。
2、数据库连接和访问要设置超时时间,避免阻塞。
8、DNS域名系统工作原理
1.查询 浏览器、操作系统 缓存。
2.请求 本地域名服务器
3.本地域名服务器未命中缓存,其请求 根域名服务器。
4.根域名服务器返回所查询域的主域名服务器。(主域名、顶级域名,如com、cn)
5.本地域名服务器请求主域名服务器,获取该域名的 名称服务器(域名注册商的服务器)。
6.本地域名服务器向 名称服务器 请求 域名-IP 映射。
7.缓存解析结果
9、ARP地址解析协议工作原理
每台主机都有一个ARP列表,存放IP地址和MAC地址的对应关系。
当源主机向目标主机发送数据时,首先查看ARP列表中IP地址对应的目标主机的MAC地址,如果找到则直接发送数据;如果找不到,就向该网段中的所有主机发送ARP请求包,里面存放源IP地址,源MAC地址,目标IP地址。
当该网段中的所有主机收到该ARP响应包之后,首先查看目标ip地址是否与自己相匹配,如果不是则忽略,如果是,就将源ip地址和源MAC地址存放到自己的ARP列表中,然后将自己的MAC地址存放到ARP响应包中发送给源主机;
目标主机收到ARP响应包,则取出对应的IP和MAC地址存放到ARP列表中,并发送数据。若未收到则ARP查询失败。
广播ARP请求,单播ARP响应。
10、连续ARQ和滑动窗口协议
连续ARQ协议:所谓连续就是在发送完一个数据帧后,不是停下来等待确认帧,而是可以连续再发若干帧,边发可以边等待确认帧,如果收到了确认帧,又可以继续发送数据帧, 由于减少了等待的时间,利用率就提高了。
但是连续ARQ在收到一个否认帧或超时后,所有该帧后面的帧都要重发而不管该帧后面的帧是否正确传送 于是便有了选择重传ARQ协议。
滑动窗口协议:允许发送方发送多个分组而不需等待确认。(滑动窗口协议是TCP使用的一种流量控制方法,此协议能够加速数据的传输)
11、HTTP和HTTPS的区别
- HTTP协议时超文本传输协议。
- HTTPS是安全的超文本传输协议,是安全版的HTTP协议,使用安全套接字层(SSL)进行信息交换。
HTTPS协议主要针对解决HTTP协议以下不足:
1.通信使用明文(不加密),内容可能会被窃听
2.不验证通信方身份,应此可能遭遇伪装
3.无法证明报文的完整性(即准确性),所以可能已遭篡改
HTTP+加密+认证+完整性保护=HTTPS
HTTP端口 80
HTTPS端口443
HTTPS采用对称加密
SSL位于应用层于传输层TCP之间,原本数据由应用层直接交由传输层处理,现在会经过SSL加密再进行传输。
HTTPS也不是绝对安全的,针对SSL的中间人攻击方式主要有两类,分别是SSL劫持攻击和SSL剥离攻击。
SSL劫持攻击就是 SSL证书欺骗攻击,将自己接入到客户端和目标网站之间; 在传输过程中伪造服务器的证书,将服务器的公钥替换成自己的公钥。
12、在浏览器中输入url地址 –>显示主页的过程
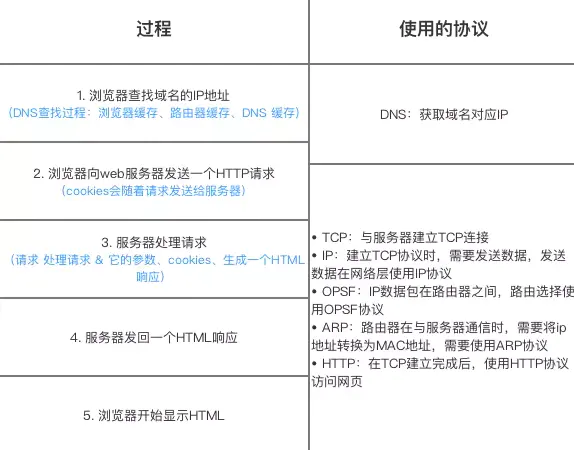
13、HTTP请求方法有哪些,用过哪些?
GET、POST、DELETE

14、IP地址的分类
A类地址(1~126):网络号占前8位,以0开头,主机号占后24位。
B类地址(128~191):网络号占前16位,以10开头,主机号占后16位。
C类地址(192~223):网络号占前24位,以110开头,主机号占后8位。
D类地址(224~239):以1110开头,保留位多播地址。
E类地址(240~255):以1111开头,保留位今后使用。

15、HTTP1.1、2.0、3.0
参考资料:
-
https://www.jianshu.com/p/5db9d0ed4b3c
一、HTTP1.1存在的问题:
- 同一时间,一个连接只能对应一个请求,这里的连接指的是
TCP三次握手建立的连接(针对同一个域名,大多数浏览器允许同时最多6个并发连接) - 一个请求只能对应一个响应(不像
HTTP2.0一样,一个请求可以有多个响应) 同一个连接的多次请求中,头信息会被重复传输(同一次连接就是指TCP三次握手和四次挥手)
二、HTTP2.0的特性:
-
HTTP2.0采用二进制格式传输数据,而非HTTP1.1的文本格式(二进制在协议解析和优化扩展上带来了更多的优势和可能)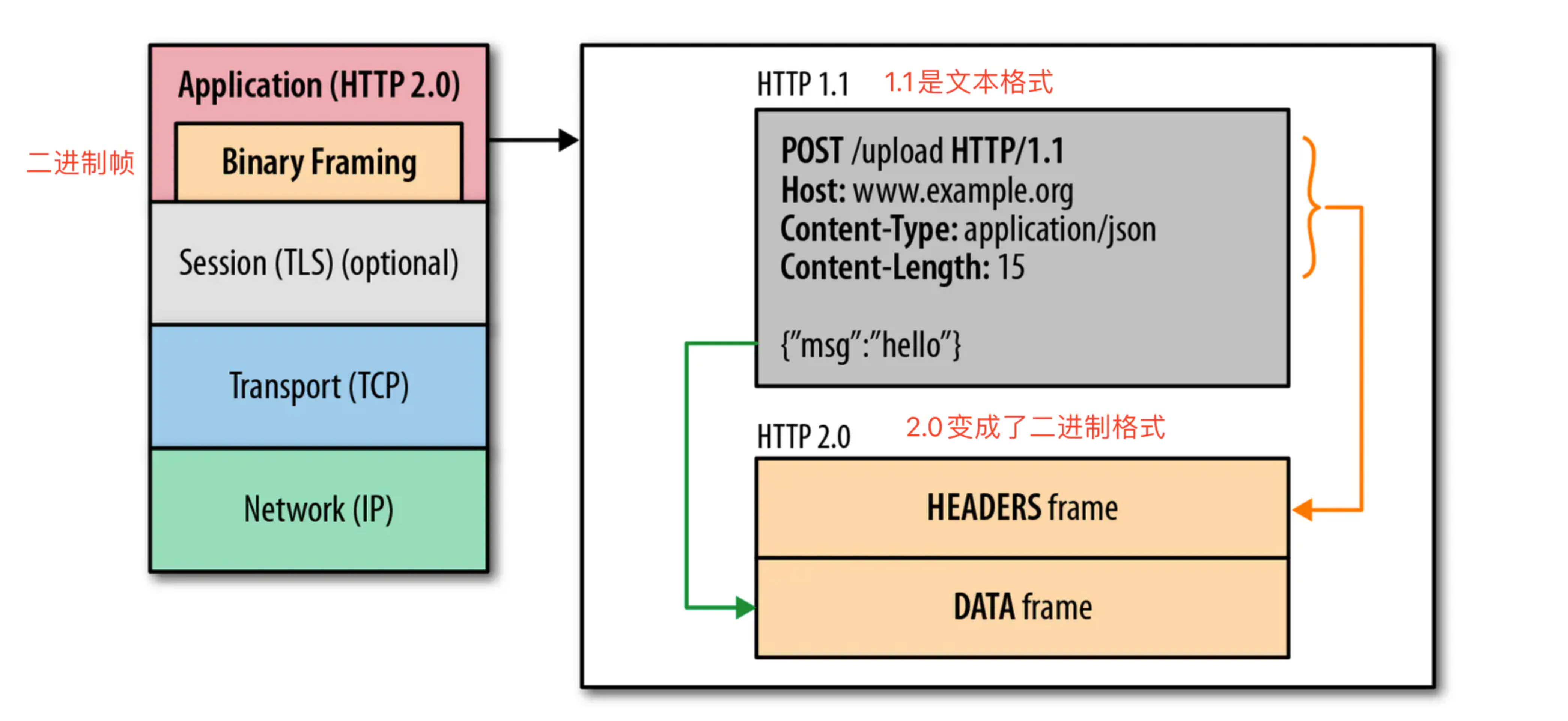
-
多路复用,就是指多个请求多个响应,可以在同一个连接中完成,而且是并发,并行交错的发送多个请求/响应,多个请求和响应之间互不影响(客户端和服务器将
HTTP消息分解为互不依赖的帧,然后交错发送,最后再另一端把它们重新组装起来),如下图所示: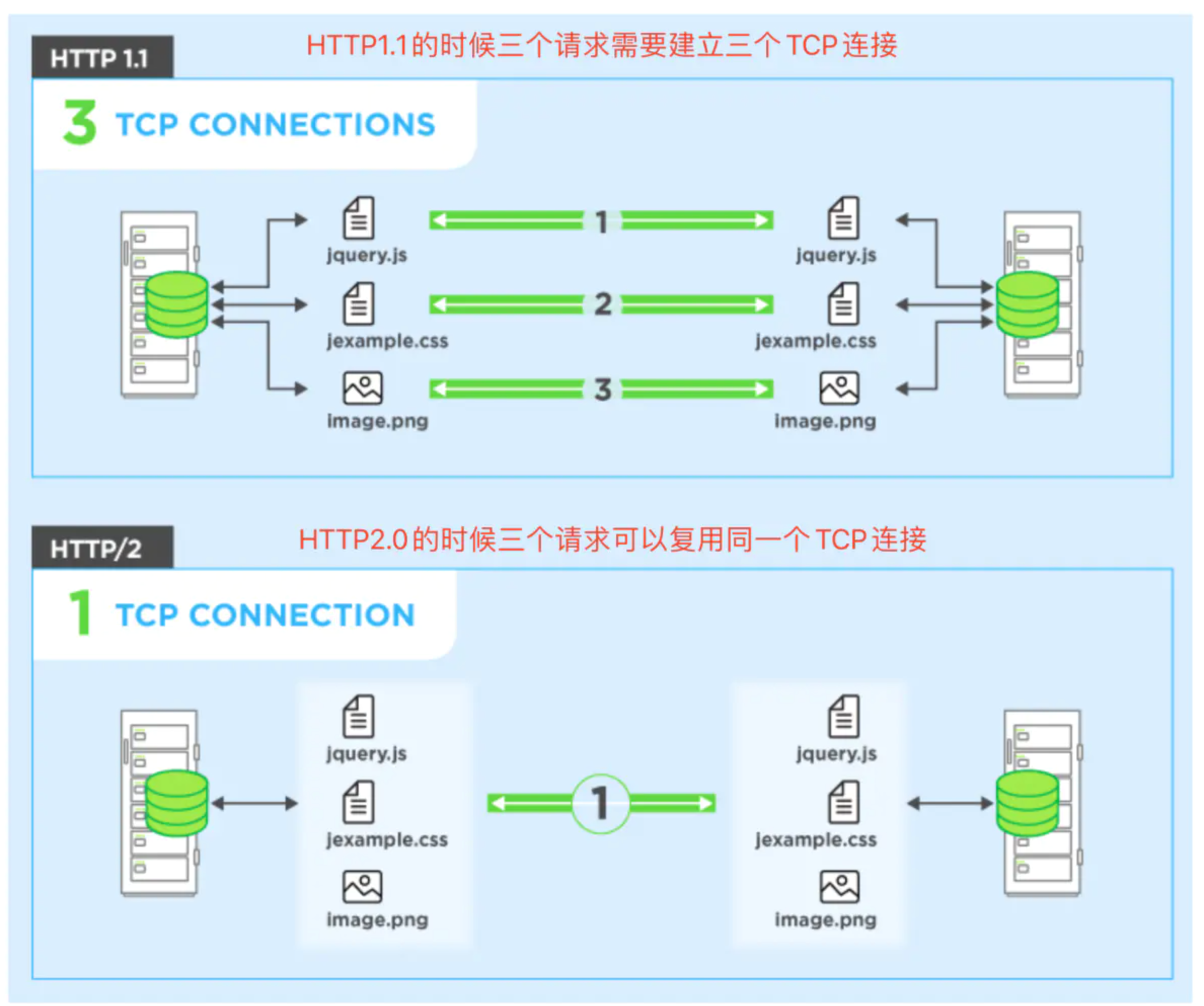
-
优先级,
HTTP2允许每个数据流都有一个关联的权重和依赖关系,权重高的可以优先发送 -
头部压缩,
HTTP2使用HPACK压缩请求头和响应头,极大减少头部开销,进而提高性能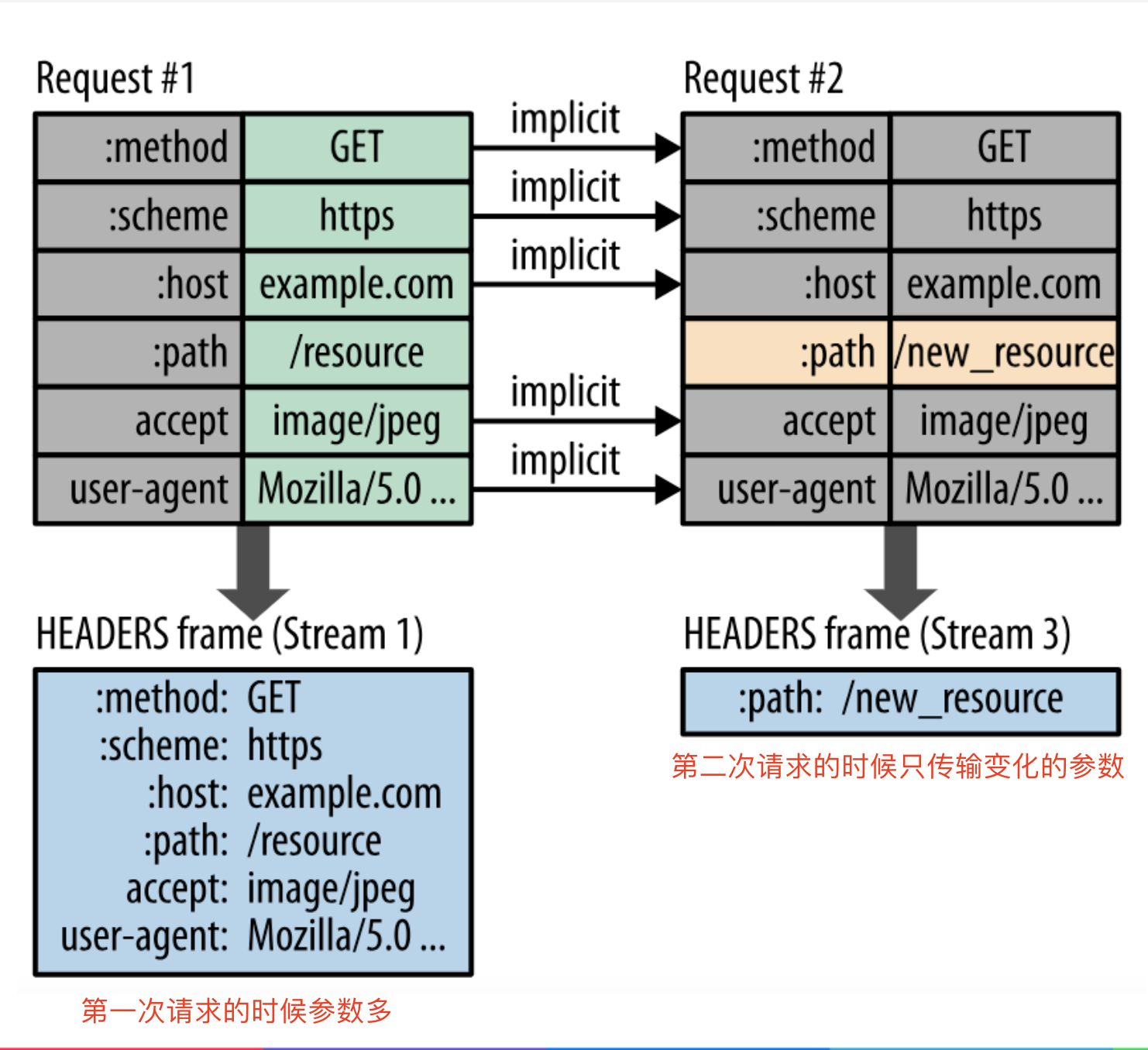
-
服务器推送,也就是一个请求可以返回多个响应(除了最初请求的响应外,服务器可以向客户端推送额外资源,而无需客户端额外的请求)
三、HTTP2.0的问题
-
队头阻塞,如果第一个包没有送达,那么后面的包无法传递给应用层,只能等待第一个包重传成功才可以传输给应用层,如下图所示:
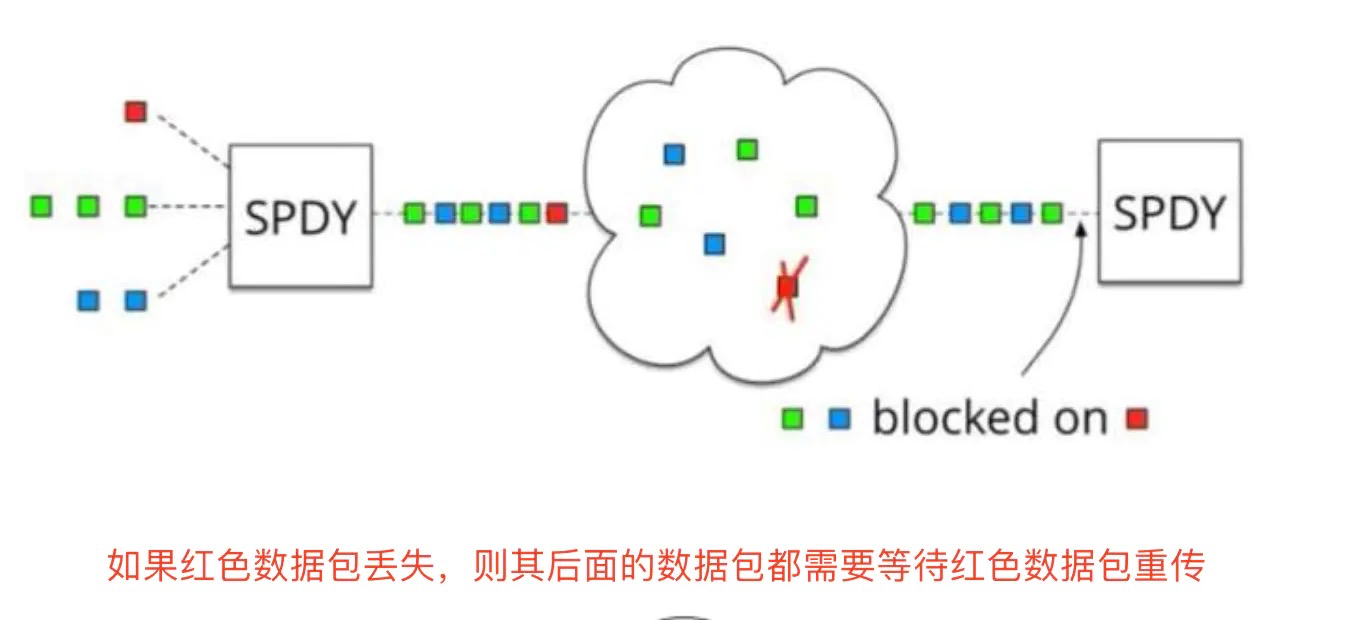
-
握手延迟,
TCP需要握手,再加上TLS需要的RTT会更多(RTT是往返时延,就是通讯一来一回的时间),不像QUIC一样,不需要RTT,QUIC只需要发送第一个UDP请求,不需要等服务器响应,就可以一直向服务器发送数据
四、HTTP3.0的特性
- 1.
HTTP3.0在传输层基于UDP协议,可靠传输是由应用层的QUIC协议来保证的,如下图所示,由于采取了UDP协议,所以使用HTTP3.0会减少传输和连接时的延时,减少网络拥塞
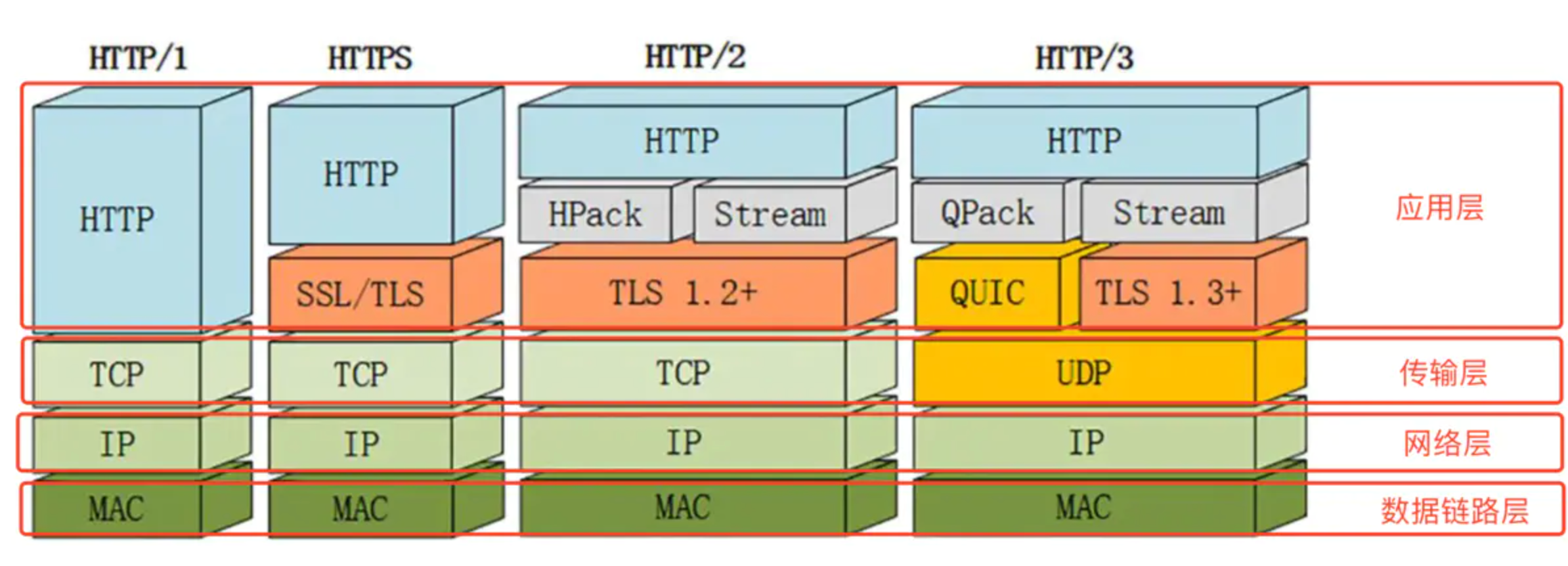
- 连接迁移,之前HTTP2.0使用的是TCP,
TCP是基于四要素建立连接的(源IP、源端口、目标IP、目标端口),只要有一个要素发生变化(例如蜂窝网络切换成WIFI,IP就会改变),就会导致连接失败,就得等原来的连接超时以后才能建立新连接;HTTP3.0使用的QUIC的连接不受四要素影响,而是使用一组的ConnectionID来标识一个连接,即使IP发生变化,只要ConnectionID不变,连接就可以维持
五、HTTP3.0的问题
与基于TLS的HTTP2.0相比,大规模部署的QUIC需要近两倍的CPU使用量,因为传统上没有使用UDP做这么大的数据传输,所以Linux内核没有对UDP做像TCP那样的优化,而且QUIC也没有硬件加速
