前言:一次艰难的图片爬虫经历
1、明确目标
这次我们需要爬取的是一个图片网站,最终目标是获取网站的全部相册集和其中的图片资源
2、难点1:右键不能使用,无法查看元素,无法查看网页源码
具体描述一下这个问题:
- 无法使用鼠标右键进行网页元素的查看
- 使用request库,无法获得网页内容,返回数据为空
- 使用selenium控制谷歌浏览器方法,也无法获得网页内容,返回数据为空
可能因为原来从来没有遇到过这种情况,暂时没有好的处理方法,但是经过我一番摸索后,想出了两种方法:
- ctrl + s 保存网页到本地,之后使用文件编辑器查看其中的源码
- 在网址前面添加view-source查看源码,类似:view-source:https://www.baidu.com/
这两种方法虽然能够手动查看源码,但是仍然无法解决程序无法获取网页源码的问题。不过能看到源码就是好的事情,我们来看一下,这个网站为了反爬,到底做了什么事情。
(1)首先怀疑引入了什么js插件,我们来看一下网页中所有的script标签

果然,发现一个可疑名称的js插件,然后我们去Google一下,果然是一个开源项目,来看一下项目给出的功能,好家伙,我说咋获取不了源码呢。
disable-devtool 可以禁用所有一切可以进入开发者工具的方法,防止通过开发者工具进行的 ‘代码搬运’
该库有以下特性:
- 支持可配置是否禁用右键菜单
- 禁用 f12 和 ctrl+shift+i 快捷键
- 支持识别从浏览器菜单栏打开开发者工具并关闭当前页面
- 开发者可以绕过禁用 (url参数使用tk配合md5加密)
- 支持几乎所有浏览器(IE,360,qq浏览器,FireFox,Chrome,Edge…)
- 高度可配置
- 使用极简、体积小巧 (仅7kb)
- 支持npm引用和script标签引用(属性配置)
- 识别真移动端与浏览器开发者工具设置插件伪造的移动端,为移动端节省性能
既然问题找到了,那该如何巧妙的绕过这个插件呢?
(2)解决问题:绕过插件
这个问题其实就比较好解决了,我们只要让网站,不加载这个js插件就可以了,那该如何操作呢?
简单!
可以通过把对应的域名映射到我们本地127.0.0.1即可,实际操作就是:修改我们的host(手动或者使用工具)
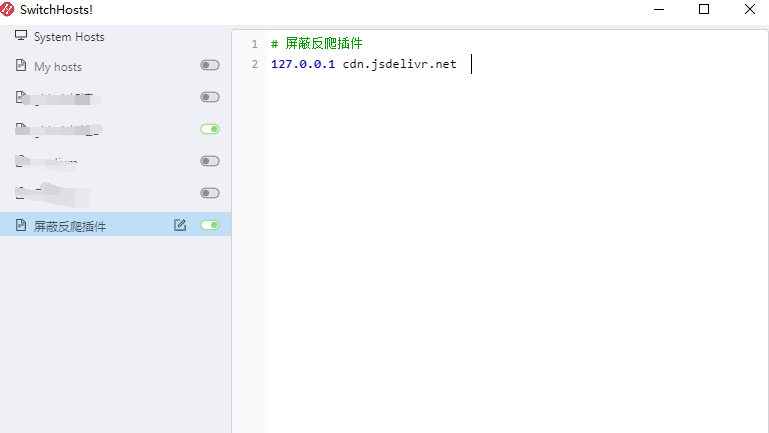
然后打开网站,f12,完美
3、难点2:如何获取全部的文章内容
经过上一步的操作,我们绕过了反爬虫的第一步,把一个反爬虫网站变成了一个普通的网站,然后就应该获取它的文章内容了。
一般情况下获取全部内容页面有三种方法:
- 页面地址规律,例如:https:xxx/page/1,可以使用程序直接模拟对应请求
- 页面地址不规律,但是有下一页button,这样可以通过selenium模拟点击的方式获取不同的页面信息
- 页面是动态加载的,一般是ajax加载。这个情况下需要我们进行观察具体的接口视情况而定了
而现在处理的这个网站,正是刚刚说的第三种情况,我们来进行具体的分析:
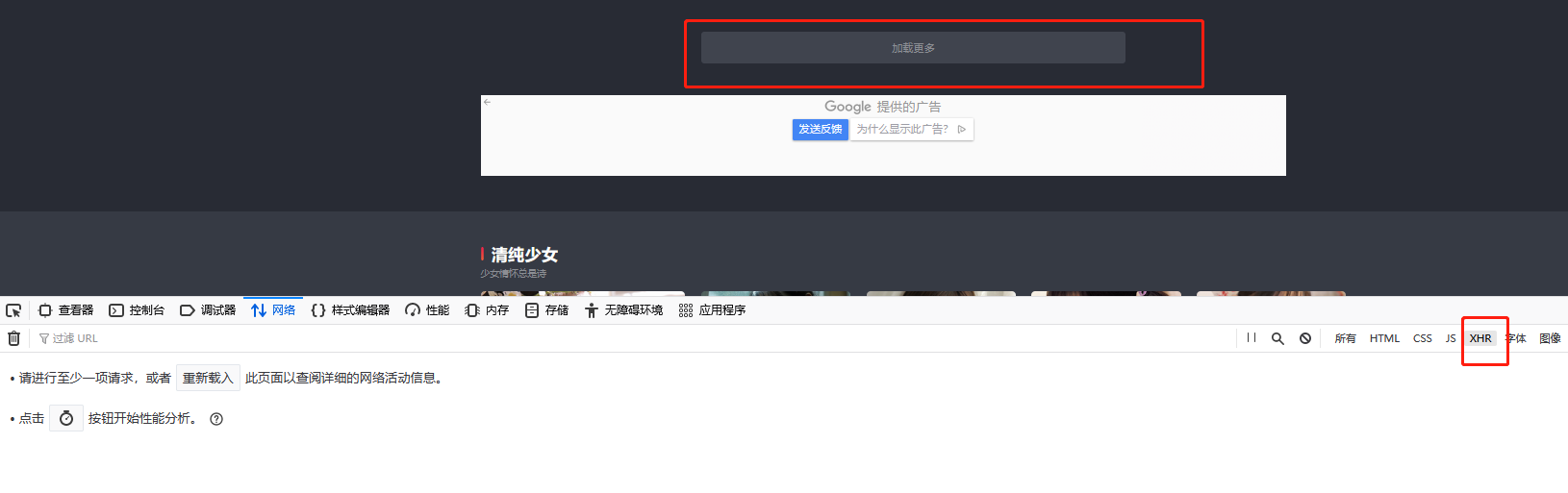
点击”加载更多”,好家伙,返回的直接是html页面代码,我还以为是json串呢,还得让我自己去手动解析,哎~
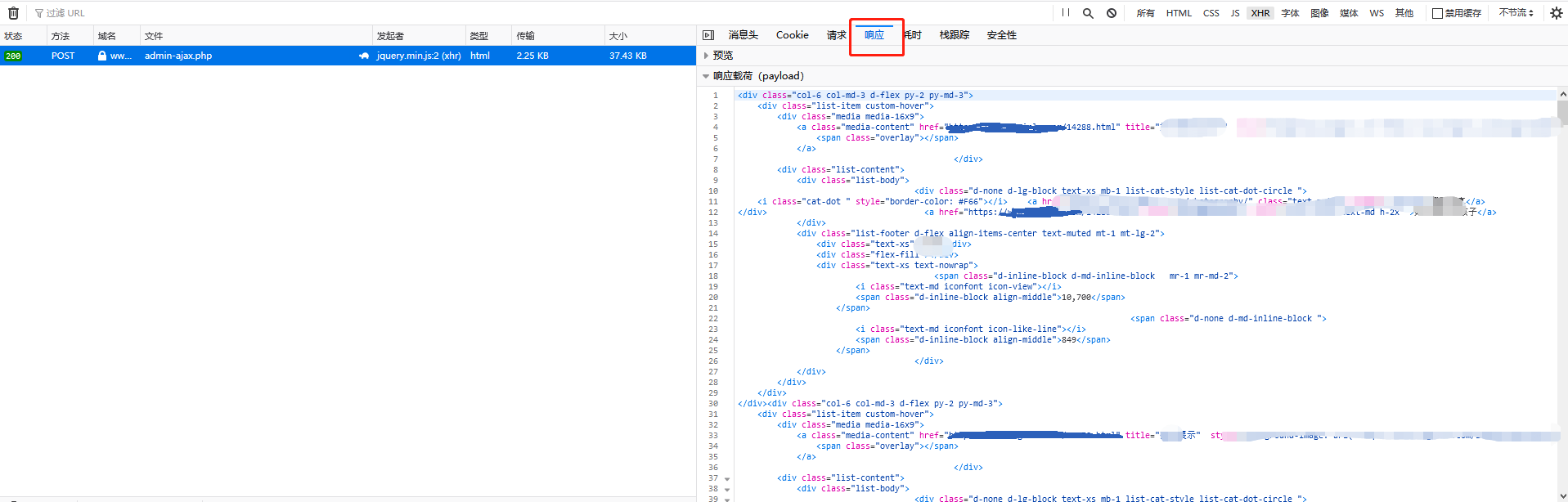
我们看一下接口的请求:
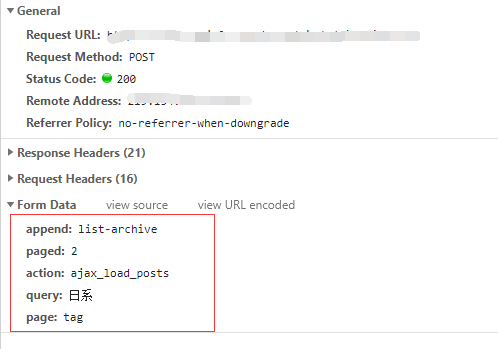
这就好办了,尝试一下在postman中构造一下post请求,完美,能够请求到
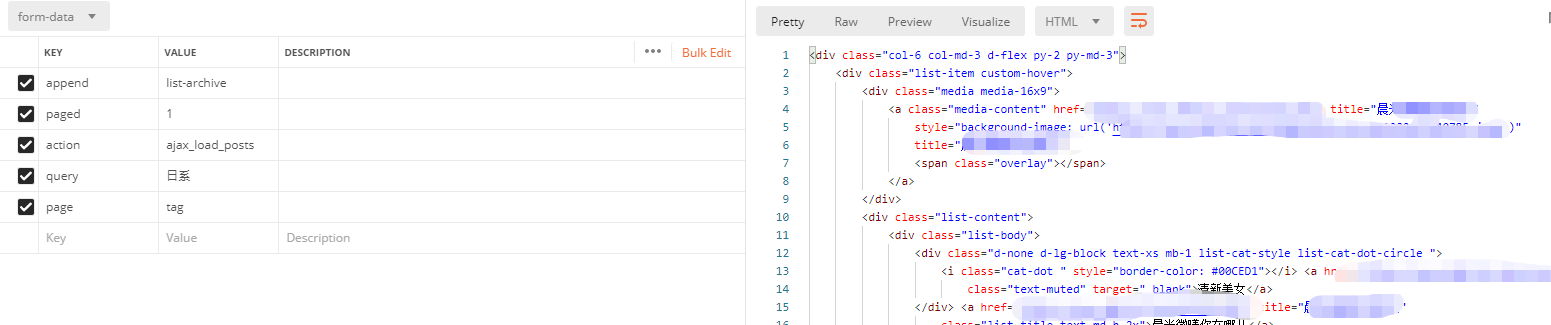
网站的tag数量不过十几种,也就是query参数我们可以用程序先写死到程序中,然后通过这个接口不断变换参数,我们就可以获得网站的所有相册源码!
注意:需要加一定的延时策略,防止IP被封
4、资源获取
接下来的事情就没有什么难度了,按照爬虫的基本流程即可,解析html网页,获取图片链接,爬取图片,没什么好谈的了
总结
第一次遇到封禁插件的网站,通过问题的解决,还是有一定收获的,其本质思路就是阻断其插件的下载
